
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- SpringBoot
- EntityTransaction
- docker
- 젠킨스
- Kotlin
- network
- 브랜치전략
- 책
- spring
- websocket
- 후기
- 리뷰
- Project
- 팀네이버 공채
- SPRING JWT
- 캐싱전략
- 스프링
- chrome80
- LazyInitialization
- 만들면서 배우는 클린 아키텍처
- Spring Security
- 프로젝트
- Java
- JPA
- jenkins
- JWT
- 팀네이버
- redis
- container
- infra
PPAK
[Kafka] 메세지큐 서버 도입과 역할의 분리 본문
현재 기존에 진행하던 프로젝트에서 예측되는 문제를 찾고 기술적으로 보완하는 리팩토링 과정을 거치고 있다.
그 중 이웃사이 프로젝트의 긴급호출 기능의 요구사항은 아래와 같다.
1. 긴급 호출 요청 시 같은 단지 내 주민들에게 알림이 간다.
1-1. 긴급 요청 알림을 통해 요청자의 위치 정보를 파악할 수 있다.
2. 긴급 호출 요청은 단지 내 주민이 수락할 수 있다.
2-1. 수락 시 단지 내 주민들에게 수락 완료 알림이 간다.
+(미정) 추후에 긴급 호출 요청 데이터를 분석하여 단지 내 발생하는 문제들의 통계를 낸다.
단순하다?
긴급 호출 기능은 굉장히 단순하다. 단순한 요청을 분석하여 같은 단지 내 주민들에게 알림을 보내주면 되기 때문이다.
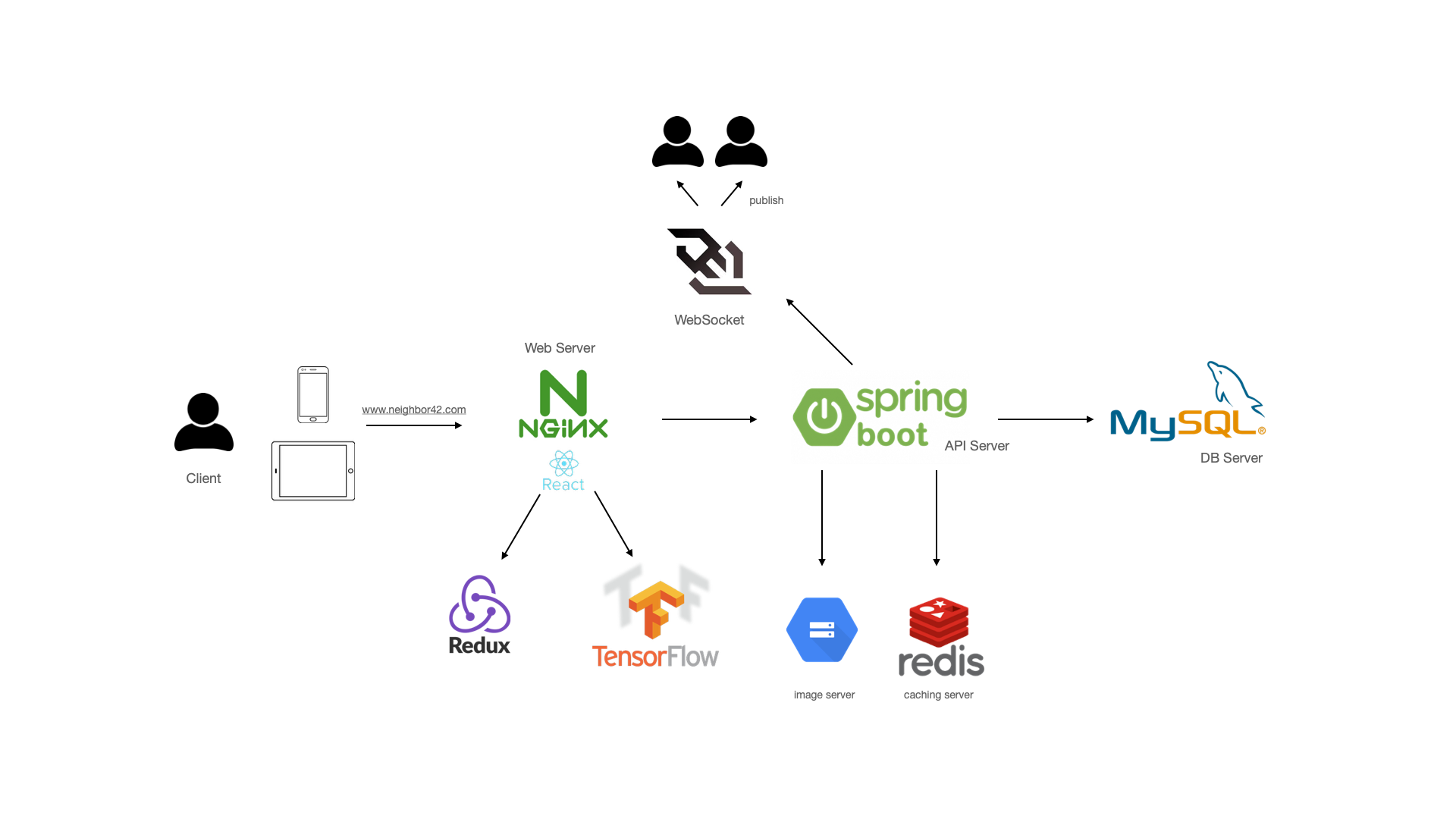
때문에 기존의 아키텍처를 살펴보면 위와 같이 서버와 STOMP + 내부 브로커를 사용해 pub/sub 구조로 웹소켓 연결을 구성함으로써 실시간으로 발생하는 긴급 호출 요청에 대한 알림을 전송하도록 설계했다.
단순하지 않다
기능적인 측면에서는 단순한 것이 맞다. 하지만 긴급 호출 요청에는 숨겨진 요구사항들이 있다.
우선 긴급 호출 요청의 경우 주민들의 안전과 직결되는 영역의 기능이기 때문에 내부적 요인(ex 프로세스 오류) 으로 인해 요청이 유실되는 경우가 있어서는 안된다.
두 번째로 긴급 호출 내역의 분석을 위해서 로그 파일을 수집하고 분석할 수 있어야 한다. 그러기 위해서 요청 내용을 저장하고 필요할 때(Scheduled Batch Job 수행 시) 데이터를 읽을 수 있어야 한다.
세 번째로 이 모든 작업이 효율적으로 이루어져야 한다.
정리하자면 긴급 호출 기능은 신뢰성이 보장돼야 하고, 요청 데이터의 영속화가 가능하면서 작업이 효율적이게 처리돼야 한다는 것이다.
다시 기존의 아키텍처를 살펴보자
위 아키텍처의 경우 서버는 긴급호출 외에도 이웃사이 서비스에서 필요한 모든 기능(역할)을 하나의 서버에서 처리하고 있다. 따라서 수많은 요청들의 경중과 상관없이 모두 동일한 자원(쓰레드) 를 나눠서 사용할 것이고, 혹여나 어느날 트래픽과 오버헤드가 큰 기능(혹은 작업) 이 추가되는 날에는 긴급 호출 기능에 대한 신뢰성, 신속성과 같은 핵심 요구사항을 만족시키지 못할 수 있다.
실제로 서버 자원이 한정적일 때 쓰레드 풀의 쓰레드가 모두 점유되고 wait queue 에서 대기하는 요청이 일정 수가 넘어가면 OutOfMemory (Heap Error) 가 발생한다.
이를 해결할 수 있는 방법은 여러가지가 있다.
1. 서버에 자원을 더 할당한다.
2. 오류 발생을 최소화 할 수 있는 방법을 도입한다. (트래픽 제한, 일정 요청 수 이상 대기 시 요청 거부)
3. 긴급 호출 요청을 처리하는 서버를 별도로 둔다.
1번 2번의 경우 요청 유실을 줄이는 방법이 될 수 있다. 하지만 여전히 하나의 서버에서 모든 기능을 수행하기 때문에 당장의 오류를 피할 수 있지만 근본적인 해결책이 되지 못한다. 특히 웹소켓 연결과 같은 경우 서버 자원을 공유하는 요청이 많이 존재하기 때문에 오류를 예측하는 것이 쉽지 않다.
오류를 탐지하고, 회복을 하는 로직도 해결책이 될 수 있지만 이는 신속성, 효율성 측면에서 요구사항을 충족시키지 못할 위험이 있기 때문에 우선 넘어갔다.
마지막으로, 기존의 서버에서 긴급호출 요청을 처리하는 서버를 별도로 두는 방식을 생각했다. 이 경우 서버는 하나의 역할에 집중해서 요청을 처리하기 때문에 오류를 예측하기 수월하고, 신속하게 요청을 처리할 수 있다는 장점이 있다.
따라서 나는 기존의 모놀리식 구조의 서버에서 긴급 호출 서버를 분리했다. 그 과정에서 추가적인 요구사항을 만족시키고자 아래와 같은 아키텍처를 구성했다.

위 아키텍처에서 한 가지 추가된 것은 긴급 호출 서버를 다시 Producer - Kafka - Consumer 구조로 분리해 Producer 서버에서 긴급 호출 요청을 전달받고, Consumer Server 에서 웹소켓 연결을 구성한다는 점인데 중간에 Kafka 를 통해 메세지를 릴레이하고 있다.
Producer, Consumer 분리? 왜?
WebSocket 과 내부 브로커로 연결을 구성하는 것은 그 자체로 자원을 많이 요구하는 작업이다. 때문에 기존의 모놀리식 구조에서도 필수적으로 분리해야하는 것이 이 웹소켓 연결을 관리하는 영역이고, 긴급 호출 요청(메세지) 의 유실을 최소화하기 위해서는 해당 영역을 별도의 서버로 다시 분리할 필요가 있었다. 결과적으로 웹소켓 서버 또한 요구되는 자원을 예측하는 것이 수월해졌다.
Kafka? 왜?

프로세스 간 데이터를 신속하게 전달 하면서도 데이터를 영속화 할 수 있어야 한다. 그리고 이 모든 과정을 안정적이고, 효율적으로 진행돼야한다. 데이터 영속화의 경우 주기적으로 진행될 긴급 요청 데이터 분석을 위해서 필수적으로 수행돼야 한다.
위와 같은 요구사항을 만족시키기 위해서는 메세지 큐를 사용할 필요가 있었다. 초기에 메세지 큐를 지원하는 Kafka 와 RabbitMQ 를 고려했다.
하지만 RabbitMQ 의 경우 메세지 전달에 초점이 맞춰져(Smart Producer) 다양한 라우팅 기법을 제공하기 때문에 데이터 처리량 자체가 Kafka 에 비해 높지 않고, 메세지가 메모리에 저장되기 때문에 한번 전달(Consume) 되면 해당 메세지를 삭제하는 전략을 사용하기 때문에 신속성과, 영속화의 요구사항을 충족시키지 못한다고 판단하여 Kafka 를 사용하기로 했다.
실제로 Kafka 는 대용량의 분산 데이터 처리에 특화된 시스템으로 데이터를 디스크에 순차적으로(물리적 배열) 저장하고, 그 처리 방식은 Consumer 에게 위임하기 때문에(Smart Consumer) 효율적인 데이터 처리가 가능하다.
또한 Consumer 그룹 별로 동일한 토픽에 대해 서로 다른 offset 을 가지기 때문에 서로 다른 시점에서 저장된 데이터를 불러와 처리할 수 있다. 이와 같은 장점 때문에 긴급 호출 요청 데이터 분석이 가능한 구조를 설계할 수 있었다.
카프카에 대한 더 자세한 설명은 본 포스팅에서는 생략하겠다.
구현
예제의 설명을 위해서 인증 부분을 제외하고 샘플 코드를 작성했다.
Kafka
카프카의 경우 zookeeper(메세지 브로커 관리), kafka 를 설치, 실행해야 한다.
Mac
brew install zookeeper
brew install kafka
brew services start zookeeper
brew services start kafka

위 이미지는 긴급 호출 시 데이터 이동을 간략하게 나타낸 것이다. 참고용으로 보면 될 것 같다.
Producer Server
Producer Server 는 클라이언트의 긴급 호출 요청을 받고 사용자 인증 절차를 거친 뒤 Kafka 에 사전에 정해진 토픽으로 메세지를 발행한다.
kafka dependency
implementation 'org.springframework.kafka:spring-kafka'우선 Spring 에서 Kafka 를 사용하기 위해서 의존성을 추가한다.
kafka config(application.yml)
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
alert-topic-name: an-alert
accept-topic-name: an-accept
server:
port: 8082간단한 Producer 설정 코드다.
Kafka 로 교환할 Value 의 경우 HashMap 으로 정했고, 이를 교환하기 위해 JsonSerializer 를 사용했다.
Topic 의 경우 각각 파티션의 크기를 2로 잡았고
긴급 호출: an-alert
긴급 호출 수락: an-accept
로 나누어 메세지를 발행했다.
요청 API Controller
@RestController
@RequiredArgsConstructor
public class ProducerController {
private final KafkaAlertProducer kafkaAlertProducer;
@PostMapping("/alert")
public void alert(@RequestBody AlertDTO dto) {
kafkaAlertProducer.alert(dto);
}
@PostMapping("/accept")
public void accept(@RequestBody AcceptDTO dto) {
kafkaAlertProducer.accept(dto);
}
}
KafkaProducer
@Service
@RequiredArgsConstructor
public class KafkaAlertProducer {
@Value("${spring.kafka.alert-topic-name}")
private String alertTopicName;
@Value("${spring.kafka.accept-topic-name}")
private String acceptTopicName;
private final KafkaTemplate kafkaTemplate;
public void alert(AlertDTO dto) {
Map<String, String> map = new HashMap<>();
map.put("line", dto.getLine());
map.put("house", dto.getHouse());
map.put("text", dto.getText());
map.put("lat", dto.getLat());
map.put("lng", dto.getLng());
kafkaTemplate.send(alertTopicName, map);
}
public void accept(AcceptDTO dto) {
Map<String, String> map = new HashMap<>();
map.put("line", dto.getLine());
map.put("accept", dto.getAcceptHouse());
map.put("target", dto.getTargetHouse());
kafkaTemplate.send(acceptTopicName, map);
}
}메세징에 필요한 데이터를 저장하고, 사전에 정한 토픽으로 메세지를 발행한다.
별도로 파티션 혹은 key 를 지정하지 않았기 때문에 default 옵션인 Round Robin 방식으로 파티션에 메세지가 분산된다.
실제로 Consumer 측에서 읽어들이는 데이터의 파티션을 확인해보면 0, 1, 0, 1 로 반복되는 것을 확인할 수 있다.
Consumer Server
Consumer Server 는 사전에 정한 토픽을 Listening 하고 메시지가 발행되는 즉시 처리할 수 있도록 설계했다.
클라이언트(주민)와 Consumer Server 는 본인의 단지로 subscribe 가 된 상태다. 따라서 서버는 긴급 호출 메세지 정보를 바탕으로
같은 단지 내 주민들에게 알림을 전달한다.
WebSocket Config
@Configuration
@EnableWebSocketMessageBroker
public class StompWebSocketConfig implements WebSocketMessageBrokerConfigurer {
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/an-ws")
.setAllowedOriginPatterns("*");
}
@Override
public void configureMessageBroker(MessageBrokerRegistry registry) {
registry.enableSimpleBroker("/sub", "/queue");
registry.setApplicationDestinationPrefixes("/pub");
}
}클라이언트의 Subscription Endpoint 는
url: ws://server domain/an-ws
{
SUBSCRIBE
destination: /sub/line/${line name}
}
로 사전에 정의했다.
WebSocket 관련 내용은 아래 포스팅을 확인하면 더 자세히 확인할 수 있다.
https://ppaksang.tistory.com/18
[Spring/WebSocket] WebSocket 도입과 STOMP subscribe, send 인가 구현
프로젝트를 기획하면서 가장 무모(?) 하게 도전한 챌린지 중에 하나가 WebSocket 사용이였던 것 같습니다. 사실 WebSocket 이라는 것도 찾아보고 안 것이지 기획 단계에서는 그저 "비동기적으로 서버
ppaksang.tistory.com
ConsumerConfig
Consumer(혹은 Listener) 를 생성하기 위해서는 KafkaListenerContainerFactory Bean 이 존재해야 한다.
따라서 아래와 같은 과정을 통해 KafkaListenerContainerFactory 의 구현체인 ConcurrentKafkaListenerContainerFactory 를 추가한다.
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String server;
private Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG, false);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
return props;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}ALLOW_AUTO_CREATE_TOPICS_CONFIG: Topic 이 존재하지 않을 때 자동 생성 여부
BOOTSTRAP_SERVERS_CONFIG: Bootstrap Server 주소 (ex localhost:9092)
AUTO_OFFSET_RESET_CONFIG: Consumer 가 추가됐을 경우 파티션의 offset 을 어느 위치로 설정할 것인가
- latest : 마지막 위치 (현 시점부터 들어오는 데이터를 읽겠다.)
- earliest : 가장 처음 offset부터 (파티션의 데이터를 모두 읽겠다.)
- none : 사전에 설정된 offset 이 존재하지 않으면 Exception 발생
KEY_DESERIALIZER_CLASS_CONFIG: Key Serializer Class
VALUE_DESERIALIZER_CLASS_CONFIG: Value Serializer Class
KafkaConsumer
@Component
@RequiredArgsConstructor
public class AlertConsumer {
private final SimpMessagingTemplate template;
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics = "${spring.kafka.alert-topic-name}", groupId = "1", containerFactory = "kafkaListenerContainerFactory"
// , topicPartitions = @TopicPartition(topic = "${spring.kafka.topic-name}", partitions = {"0"})
)
public void alert(ConsumerRecord consumerRecord) {
logger.info("[Consume] alert");
logger.info(consumerRecord.partition() + "");
HashMap<String, String> message = (HashMap<String, String>) consumerRecord.value();
String line = message.get("line");
String house = message.get("house");
String text = message.get("text");
Map<String, String> payload = new HashMap<>();
payload.put("type", "alert");
payload.put("line", line);
payload.put("house", house);
payload.put("text", text);
Map<String, Object> header = new HashMap<>();
header.put("type", "alert");
template.convertAndSend("/sub/line/"+line, payload, header);
}
@KafkaListener(topics = "${spring.kafka.accept-topic-name}", groupId = "1", containerFactory = "kafkaListenerContainerFactory"
// , topicPartitions = @TopicPartition(topic = "${spring.kafka.topic-name}", partitions = {"1"})
)
public void accept(ConsumerRecord consumerRecord) {
logger.info("[Consume] accept");
logger.info(consumerRecord.partition() + "");
HashMap<String, String> message = (HashMap<String, String>) consumerRecord.value();
String line = message.get("line");
String accept = message.get("accept");
String target = message.get("target");
Map<String, String> payload = new HashMap<>();
payload.put("type", "accept");
payload.put("line", line);
payload.put("accept", accept);
payload.put("text", target);
Map<String, Object> header = new HashMap<>();
header.put("type", "accept");
template.convertAndSend("/sub/line/"+line, payload, header);
}
}Consumer 의 경우 alert(긴급 호출 알림), accept(긴급 호출 수락) 기능 별로 사전에 정의된 토픽을 Listening 하도록 설정했다.
따라서 파티션에 관계없이 해당 토픽으로 발행된 메세지를 불러와서 처리한다.
@KafkaListener 내에 주석된 코드를 사용하면 특정 파티션에 저장된 메세지만 선택적으로 불러올 수도 있다.
마무리
여기까지 초기에 설계한 구조를 모두 완성했고 요청이 성공적으로 전달 되고, 메세지가 발행되는 것을 확인할 수 있다.
서버를 분리하면서 느낀 것은 확실히 단일 프로젝트 구조가 단순해져서 코드를 수정하는 것도 수월하게 진행할 수 있겠다는 것이다.
웹소켓 서버 같은 경우에는 내부 브로커를 사용하면서 프로세스가 증가할 경우 세션 유지에 대한 고민이 있었는데 Kafka 를 통해 메세지를 릴레이하는 구조가 유지 된다면 별개의 서버에서 동일한 메세지를 처리할 수 있겠다고 생각했다.
결과적으로 기존 하나의 서버에서 처리되는 요청을 여러 대의 서버로 분산 처리할 수 있도록 설계했다. 그 과정에서 Producer, Consumer 서버 간의 의존도를 낮추기 위해 비교적 복잡도가 낮은 Kafka 와 메세지 프로토콜에 의존적으로 설계해서 기존보다 더 수월하게 프로젝트를 관리할 수 있도록 했다.
최근 프로젝트 리팩토링 과정을 진행하면서 많은 것을 느끼고 있다. 특히 기능 구현의 비중이 높던 때와는 달리 "이 프로젝트가 과연 운영 가능한가?" 에 초점을 맞추어 보완이 필요한 부분을 찾고 개선해 나가고 있다. 그 과정에서 주변 현업에 종사하고 계신 멘토님들과 선배님들의 조언이 특히나 큰 도움이 되었다. 여전히 실무에서 운영되는 아키텍처에 비하면 부족하디 부족한 프로젝트지만 그렇기 때문에 꾸준히 개선하고 검증해봐야겠다는 생각이 들었다.
'infra' 카테고리의 다른 글
| Github Actions 괜찮네 (7) | 2024.02.11 |
|---|---|
| [Hazelcast] Distributed Computing (Predicate) (2) | 2023.09.28 |
| [CI/CD] 프로젝트 무중단 배포 도입기 (2) | 2023.01.04 |
| [CI/CD] Docker 에서 SpringBoot 구동하기 (2) | 2022.07.24 |
| [CI/CD] Git Webhook 을 통한 Jenkins-Spring Boot 빌드, 배포 자동화 (2) | 2022.07.24 |



