
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- LazyInitialization
- 프로젝트
- 만들면서 배우는 클린 아키텍처
- infra
- chrome80
- EntityTransaction
- 후기
- 스프링
- Java
- Project
- jenkins
- SpringBoot
- container
- 캐싱전략
- websocket
- network
- Kotlin
- 팀네이버 공채
- 젠킨스
- JPA
- 리뷰
- 책
- SPRING JWT
- 팀네이버
- 브랜치전략
- redis
- spring
- docker
- JWT
- Spring Security
PPAK
Redis 캐싱 전략 개선 및 스케줄링 본문
기존에 진행하던 프로젝트에서 Redis 를 사용해 캐싱과 이벤트를 공유하는 로직을 추가했다.
캐싱의 경우, 우선 시스템 내에서 자주 조회 되면서 시스템 내에 존재하는 데이터 간 연관 관계가 복잡하지 않은 (혹은 수정 가능성이 낮은) 데이터를 중심으로 수행했다.
따라서 인증 정보와 좋아요 기능을 위한 캐싱을 수행하기로 했고 아래 두 가지의 요구사항에 따라서 로직을 구성했다.
1. 인증 정보의 교환에서 세션 정보를 서버에 저장하지 않고 JWT 를 통해 인증/인가 진행. 잦은 Access Token 발급을 방지하기 위해 Refresh-Access 토큰 쌍을 일정 시간 동안 캐싱할 때 Redis 를 사용했다.
덕분에 여러 대의 서버에서 동일한 Redis 의 캐싱 정보를 사용할 수 있었고, 시스템 자원의 낭비를 사전에 막을 수 있었다.
또한 그 과정에서 JWT 의 특징을 이해하고, 인증 정보의 송수신 안정성을 높이기 위해 여러 가지 고민을 할 수 있었다.
https://ppaksang.tistory.com/16 참고
[Spring/JWT] Access Token 과 Refresh Token 을 어디에 저장하고 어떻게 교환해야 할까?
제가 서버에 채택한 인증 방식은 JWT 를 활용한 Access Token 교환 방식입니다. 서버 측에서는 사용자가 정상적으로 로그인을 마치면 사용자 인증 정보를 포함하는 Access Token 과 이를 재발급할 수 있
ppaksang.tistory.com
2. 오늘 포스팅의 주제이기도 한 좋아요 기능과 관련해 캐싱 전략을 사용했다.
좋아요의 경우 잦은 조회가 발생하는 영역이고, 그 데이터가 (게시글 ID, 사용자 프로필 ID) 와 같이 앞으로도 변할 확률이 낮고 하나의 데이터쌍으로 구성되어 있기 때문에 삽입/삭제하기 용이할 것이라고 판단해 캐싱을 수행하기로 계획했다.
또한 좋아요 요청의 경우 동시에 데이터 쓰기 요청이 몰릴 수 있는데 Redis 가 Single Thread 로 동작하는 점을 이용해 데이터 수정 요청을 처리한다면 동시성 문제도 발생하지 않을 것이라고 판단했다.
여기서 인증 정보를 저장할 때와는 또 다른 요구 사항이 존재했다.
먼저 인증 정보의 경우 휘발성 데이터로 메모리(Redis) 상에만 존재해도 충분하다. 하지만 좋아요의 경우 시간이 지나도 그 데이터가 남아있어야 하기 때문에 간단하게 생각해봐도 데이터베이스에 영속화를 하는 과정이 분명 필요하는 것을 알 수 있다.
그렇다면 여기서 한 가지 고민이 생길 수 있다. "캐싱과 영속화를 동시에 수행할 수 있나?" 절차만 놓고 본다면 간단할 수 있다.
1. 캐시에 저장하고
2. 디비에 저장하고
. . . ? 이럴 거면 캐싱을 왜 하지 라는 생각이 들 수 있다
캐시 쓰기 전략
여전히 새로 생성된 데이터를 조회하는 과정에서 성능상 이점을 가지기 때문에 위와 같은 방법도 아주 비효율 적인 방법은 아니다.
실제로 위와 같이 캐시 쓰기 상황 에서 캐시 저장 -> 디비 저장의 순서를 가지는 것을 Write Through 패턴이라고도 한다.
하지만 위와 같은 방법을 살펴보면 알 수 있듯 캐시, 디비에 데이터를 동시에 저장하기 때문에 사용자에게 응답을 늦게 전달할 수 있다. (Response Latency 증가) 따라서 본 프로젝트에서 좋아요 수와 같이 빈번하게 수정되는 데이터에는 적합하지 않다.
다음으로 Write Around 패턴을 살펴보자
Write Around 패턴은 모든 데이터를 곧바로 디비에 저장하고 조회 단계에서 cache miss 시 캐시에 저장하는 방식을 의미 한다.
이 경우 쓰기는 자주 발생하지만 조회는 가끔 발생하는 경우에 적합하다. 역시 좋아요 기능과 같이 조회/쓰기가 빈번하게 발생하는 경우에 맞지 않다.
마지막으로 Write Back 패턴이다
쓰기 작업은 항상 캐시에 수행하고, 스케줄링을 통해 주기적으로 디비에 캐시 데이터를 옮겨주는 것을 의미한다. 이 경우 쓰기와 읽기가 자주 일어나고 응답 속도가 중요할 때 사용할 수 있는 전략이다. 해당 전략을 사용할 경우 데이터 누락에 대해서 처리를 해야 하지만 좋아요와 같이 데이터 누락에 대해 상대적으로 관대한 데이터의 경우에 적합한 전략으로 판단하고 해당 방식으로 캐싱과 영속화 과정을 진행하기로 했다.
로직을 설명하기 전에 읽기(조회) 전략에 대해서도 잠깐 알아보자
캐시 읽기 전략
캐시 읽기 전략의 차이는 cache miss 가 발생했을 때 어떻게 대응하냐에 따라 나뉘는데
cache miss 가 발생했을 때 곧바로 DB 에서 불러와 캐시에 저장하고, 캐시에서 데이터를 다시 읽어 오는 것을 Read Through 전략 이라고 한다.
반대로, 캐시에서 읽을 수 있는 데이터는 캐시에서 읽고 cache miss 시 디비에서 읽는 방식을 말하는데 Look Aside 패턴 이라고도 한다. Read Through 와 달리 데이터베이스, 캐시 모두에게서 데이터를 불러올 수 있기 때문에 시스템 안정성이 더 높다고 볼 수 있다.
기존 코드
기존 코드의 경우 Look Aside & Write Through 전략을 사용하려 했지만 DB Transaction 이 실패 했을 때에 대한 롤백 처리 혹은 쿼리 재실행 전략을 따로 구성하지 않았기 때문에 완벽한 Write Through 기법을 썼다고 볼 수 없다. 이 경우 트래픽이 몰렸을 때 DB insert/update query 가 빈번하게 발생해 응답이 굉장히 느려지는 것은 물론이고, 데이터 정합성에 대한 심각한 오류를 초래할 수 있다. 또한 요청에 대한 응답 속도를 고려했을 때 Write Back 전략으로 바꿀 필요가 있었다.
데이터의 경우 게시글 ID 당 좋아요를 누른 Profile ID 의 집합(Set) 을 저장했다.
...
public class ExpressionService {
...
private static final long duration = 3600*24*100;
@Transactional
public void save(CreateExpressionForm form, Long profileId) {
Community community = communityRepository.findById(form.getCommunityId())
.orElseThrow(() -> new NotFoundException("글이 존재하지 않습니다."));
Profile profile = accountRepository.findProfileById(profileId)
.orElseThrow(() -> new NotFoundException("존재하지 않는 프로필입니다."));
String key = keyPrefix + form.getCommunityId();
if(!redis.exists(key)) DBtoCache(form.getCommunityId());
if(redis.sIsMember(key, profileId)) {
redis.sRem(key, profileId);
Expression findEx = expressionRepository.findByBoardIdnProfileId(form.getCommunityId(), profileId)
.orElseThrow(() -> new IllegalStateException("비정상적인 데이터"));
expressionRepository.delete(findEx);
} else {
redis.sAdd(key, profileId);
redis.expire(key, duration);
Expression expression = Expression.builder()
.board(community)
.profile(profile)
.build();
expressionRepository.save(expression);
}
}
}
개선 코드 (Look Aside & Write Back)
기존의 (캐시 쓰기 + 디비 쓰기) 방식에서 캐시 쓰기만 남기고 코드를 모두 삭제 했다.
로직은 요청 Profile Id 가 집합에 존재하는지 여부에 따라 삽입/삭제를 수행했다.
또한 Update 된(쓰기 요청이 한 번이라도 수행된) 게시글에 대해서는 추후 스케줄링 단계에서 디비와 동기화가 필요한 데이터라는 의미로 별도로 데이터(keyUpdate)를 저장했다.
캐시 쓰기
...
public class ExpressionService {
...
private static final long duration = 3600*2; // 2시간
public void save(CreateExpressionForm form, Long profileId) {
String key = String.format(keyPrefix + "%s", form.getCommunityId());
if(!redis.exists(key)) DBtoCache(form.getCommunityId());
if(redis.sIsMember(key, profileId)) redis.sRem(key, profileId);
else {
redis.sAdd(key, profileId);
redis.expire(key, duration);
}
redis.sAdd(keyUpdate, form.getCommunityId());
redis.expire(key, duration);
}
}
스케줄링(Write Back)
캐시에 좋아요 목록이 저장된 게시글에 대해 수정이력이 있는 경우(위의 쓰기 연산이 수행된 게시글) 스케줄링 작업에서 디비와의 동기화 대상이 된다.
결과적으로 아래와 같은 짧은 코드를 작성했는데, 해당 코드를 작성하기 위해서 팀원인 아양님과 적지않은 고민을 한 것 같다...
고민을 하는 과정에서 해결하고자 했던 문제는 데이터 누락을 완전히 막는 것이였는데 결과적으로 데이터 누락을 완전하게 막지는 못했다(뒤에 추가적으로 이야기하겠지만 실보다는 득이 많은 선택이라고 생각한다)
로직을 설명하기 전 스케줄링 요구사항은 아래와 같았다.
1. 캐시에 존재하는 모든 데이터를 주기적으로 디비와 동기화 해야한다.
2. 그 과정에서 데이터 누락이 없어야(최소화) 한다.
3. Redis 에 데이터가 저장되어 있을 때(데이터가 expired 되기 전) DB 에 데이터를 옮겨야 한다
스케줄링 로직
로직은 간단하다. 수정된 게시글(좋아요 수정이 일어난 게시글) 목록을 불러와서 해당 게시글 ID 로 다시 현재 캐시 데이터(좋아요를 누른 Profile ID) 를 조회해 디비에 저장하는 방식이다. (저장하는 과정에 대한 구체적인 로직은 이어서 작성하겠다)
디비에 저장하는 과정에서 실패하는 경우 롤백을 수행하고, 다시 스케줄링 목록에 추가하도록 했다.
데이터 누락 최소화
데이터의 경우 조회, 수정이 발생하면 2시간 단위로 expire 주기를 갱신해 주었고, DB 동기화 스케줄링 작업은 50분 단위로 수행하기 때문에 쓰기작업이 일어난 게시글 당 데이터가 expired 되기 전 최소 2번 이상의 스케줄링 작업의 대상이 되고, 동기화가 정상적으로 수행되지 않으면 다시 스케줄링 대상에 포함하는 로직을 추가했기 때문에 데이터 누락을 최소화 할 수 있었다.
@Service
@RequiredArgsConstructor
public class ScheduleService {
...
private static final long duration = 3600*2; // 2시간
@Scheduled(fixedDelay = 3000000L) // 50분 마다
public void cacheToDB() {
Set<Long> updatedIds = redis.sMembers(keyUpdate).stream().map(i -> Long.valueOf((Integer) i)).collect(Collectors.toSet());
// 이 시점에 다른 게시물에 대한 좋아요 변경사항이 생길 경우 expire하기 전에 또 다른 변경사항이 생기지 않으면 누락됨, expire 하기 전에 화면에는 보임
redis.del(keyUpdate);
for(Long boardId : updatedIds) {
Set<Long> updates = redis.sMembers(String.format(keyPrefix + "%s", boardId)).stream().map(i -> (Long) i).collect(Collectors.toSet());
try {
expressionService.store(boardId, updates);
} catch (Exception e) {
redis.sAdd(keyUpdate, boardId);
}
}
}
}
문제점
스케줄링 코드를 살펴보면 캐시에서 key 를 통해 데이터를 불러오고, key 를 삭제하는 코드가 있다. 해당 작업은 하나의 Transaction 으로 이루어져야 하지만 Redis 에서는 get 메소드에 대해 Transaction 내에서 항상 null 을 반환한다.
이유는 Redis 의 Transaction 은 exec() 메소드가 호출되기 전까지의 모든 명령을 버퍼에 담아 두었다가 레디스에 전송하는 방식인데, 그렇게 이후 시점에 get 으로 불러온 데이터는 의미가 없다고 하여 null 을 반환한다고 한다.
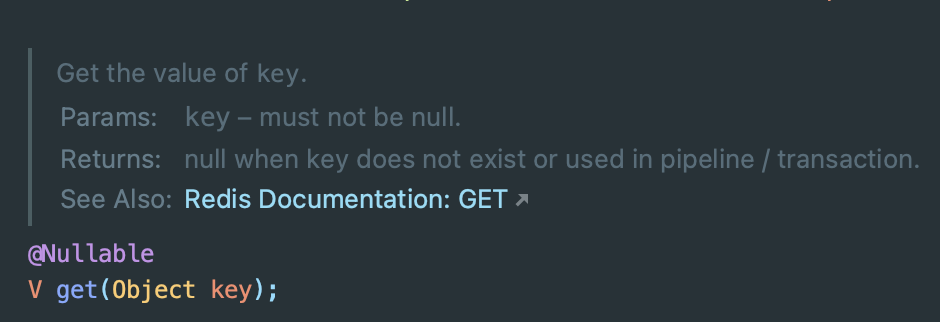
대안으로 Redis 에서 제공하는 낙관적 락을 통해서 아래와 같이 부분 Transaction 을 구성하는 방법에 대해서도 고민해봤다.
우선 공식적으로 보장하는 방식이 아니라 조금 더 검토가 필요할 것 같다.
public void example() {
redisTemplate.watch(keyUpdate);
String value = redis.get(keyUpdate);
if (value != null) {
redisTemplate.multi();
//Logic
redisTemplate.exec();
}
redisTemplate.unwatch();
}또한 우아콘의 이벤트 기반 아키텍처 구축하기 영상을 보고 Redis 와 DB 의 다중 데이터베이스 분산 트랜잭션을 보장하는 것이 쉽지 않다는 것을 알았고, 영상에서는 데이터 유실이 없어야 하는 요구사항 때문에 속도와 성능을 위한 Redis 를 포기하고, 하나의 DB 를 이용해 트랜잭션을 보장했다면 (Transactional Outbox Pattern), 본 프로젝트의 좋아요와 같은 데이터는 누락되는 데이터가 발생하는 것에 대해 상대적으로 낙관적이고, 응답성이 더 중요한 영역이라 위에서 언급한 로직을 그대로 사용하기로 결정했다.
마무리
아직 다중 데이터베이스 분산 트랙잭션을 보장하는 것에 대해서 더 고민이 필요한 것 같다. 사실 지금 가장 궁금한 것은 현업에서는 비슷한 요구사항에 어떻게 대응하고 있느냐인데 이번 기회를 통해 여러가지 문서를 살펴보았지만 100% 만족하지는 못한 것 같다.
그래도 초기 캐싱 전략과 비교해서 캐싱 전략을 개선함으로서 데이터 누락률을 감소시키고, 사용자의 응답 속도를 개선시킬 수 있는 방법에 대해 고민할 수 있었다.
최근 기존에 진행했던 프로젝트를 더 현실적인 관점에서 바라보고, 운영가능성에 초점을 맞추어 시스템의 안정성과 효율성에 대해 고민을 하고 있는데 그 과정에서 정말 많은 것을 배우는 것 같다. 앞으로도 꾸준히 노력해야겠다 !!!
'프로젝트' 카테고리의 다른 글
| 테스팅 (3) | 2023.05.28 |
|---|---|
| 알림 전송 모듈 개발기 (6) | 2023.03.10 |
| [프로젝트 리뷰] 주어진 시간은 단 5일 (feat.핀플레인) (2) | 2022.10.08 |
| [프로젝트 리뷰] 공개SW 개발자 대회 참여를 하면서 (feat. 이웃사이) (0) | 2022.09.10 |
| [Spring/WebSocket] WebSocket 도입과 STOMP subscribe, send 인가 구현 (1) | 2022.08.31 |



