
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 스프링
- SPRING JWT
- docker
- 젠킨스
- spring
- SpringBoot
- Spring Security
- 캐싱전략
- Java
- jenkins
- redis
- 리뷰
- LazyInitialization
- 팀네이버
- Project
- websocket
- EntityTransaction
- 후기
- Kotlin
- 브랜치전략
- network
- 팀네이버 공채
- 프로젝트
- 만들면서 배우는 클린 아키텍처
- container
- infra
- 책
- JPA
- chrome80
- JWT
PPAK
Hazelcast 를 사용하며 본문
블로그에 Hazelcast 관련 포스팅을 했었는데 실제 서버를 운영하면서 느낀점을 포스팅 해본다.
https://ppaksang.tistory.com/35
[Hazelcast] Distributed Computing (Predicate)
이번 포스팅에서는 Hazelcast를 프로젝트에서 사용하면서 정리한 내용을 간단하게 적고, 내가 겪은 Hazelcast 관련 문제에 대한 상황과 해결(?)한 방법을 설명하고자 한다. 본 포스팅에서는 Hazelcast 환
ppaksang.tistory.com
Hazelcast란?
Hazelcast는 여러 대의 컴퓨터 메모리를 하나의 메모리처럼 사용할 수 있는 IMDG(In-Memory Data Grid)를 지원하는 캐시 솔루션이다. 이 IMDG 기술을 사용해 Hazelcast는 클러스터를 구성하여 데이터를 분산 저장하고, 이를 기반으로 빠르고 확장 가능한 아키텍처를 제공한다.
Peer-to-Peer 방식의 데이터 분산 처리
Hazelcast의 가장 큰 특징 중 하나는 Peer-to-Peer 방식으로 데이터를 저장하고 처리한다는 점이다. 즉, 클러스터를 구성하는 모든 노드가 동등한 역할을 하며, 데이터를 서로 공유하고 복제한다. 이러한 구조 덕분에 하나의 노드가 장애를 일으키더라도 다른 노드가 자동으로 데이터를 분배하고 처리할 수 있어 높은 가용성(Availability)을 보장한다.
데이터 분산 및 복제 방식
Hazelcast는 데이터를 파티션(Partition) 단위로 나누어 저장한다.
- 키(Key) 기반의 해시 함수(Hash Function) 를 이용해 특정 파티션에 데이터를 저장한다.
- 각 파티션은 백업본(Replica) 을 생성하여 여러 노드에 분산 저장된다.
- 특정 노드가 다운되거나 장애가 발생하면, Hazelcast는 백업본을 활용하여 자동으로 데이터를 재분배한다.
이러한 데이터 분산 및 복제 방식 덕분에 Hazelcast는 데이터 유실을 방지하면서도 높은 성능과 확장성을 제공할 수 있습니다.

구성
Hazelcast 는 크게 Member 와 Client 로 컴포넌트가 나뉜다고 볼 수 있는데
Member 는 실제 데이터를 저장하고 데이터를 분산 처리하는 노드의 역할을 수행한다고 볼 수 있고 Client 는 이 Member 에 접근해 데이터를 읽고 쓰는 주체를 의미한다. (물론 Client 도 내부적으로 Near Cache 를 사용해 데이터를 일부 저장한다)
k8s
Hazelcast 를 운영하면서 느낀 이점중 하나는 k8s 클러스터에서 배포하고 확장하기 편리하다는 것이다.
간단한 namesapce, service-name 설정과 k8s Rolebinding 구성만 하고 Helm Chart를 구성하기만 하면 바로 배포가 가능하다 🫨
이것이 가능한 이유가 Hazelcast 에서 지원하는 Auto Discovery 덕분인데 이것을 사용하면 Member 자체적으로 새 Member 가 추가되는 상황을 감지하고 peer-to-peer 방식으로 파티션 리밸런싱을 수행한다. 이로 인해 기존 클러스터 구조를 유지하면서도 저장할 수 있는 데이터의 총량을 쉽게 확장할 수 있다.
또, 이 과정에서 데이터를 여러 Member 에 걸쳐서 백업을 하기 때문에 한 노드가 죽더라도 백업본이 저장된 다른 노드에서 데이터를 서빙하기 때문에 전체적인 클러스터 가용성을 높일 수 있다
https://docs.hazelcast.com/hazelcast/5.5/kubernetes/kubernetes-auto-discovery
Kubernetes Auto Discovery | Hazelcast Documentation
By default, Hazelcast distributes partition replicas (backups) randomly and equally among cluster members. However, this is not safe in terms of high availability when a partition and its replicas are stored on the same rack, using the same network, or pow
docs.hazelcast.com
Member - Client
애플리케이션과의 연동 구조는 데이터 처리 주체인 Hazelcast-Member와 Hazelcast-Client가 통신하는 방식으로 이루어진다.
각 애플리케이션에는 Near Cache라 불리는 로컬 캐시가 존재하는데, 이러한 Near Cache에 자주 조회되는 데이터를 클라이언트 측에 캐시하여, 네트워크 트래픽을 줄이고 성능을 향상시키는데 사용된다.
또한 Near Cache는 클라이언트의 로컬 메모리에서 작동하기 때문에, 클라이언트의 인스턴스를 늘리기만 해도 클러스터와 독립적으로 확장할 수 있다.
로컬 캐시를 사용할 경우, 데이터 일관성 문제가 발생할 수 있다고 생각할 수 있는데, Hazelcast는 데이터가 변경되었을 경우 무효화(invalidation) 이벤트를 전파해서 클러스터 내에 있는 노드가 동일한 데이터를 갱신할 수 있도록 유도한다. 무효화(invalidation) 이벤트가 유실되는 상황까지 감지하여, 데이터가 오래된 경우 자동으로 데이터를 갱신하는 정책 또한 제공한다.
실제로 읽기 부하가 많은 요청의 경우 네트워크 홉을 줄이는 것도 하나의 성능 개선이 될 수 있는데, Near Cache 존재 자체로 그 고민을 상당히 줄여주었던 것 같다.
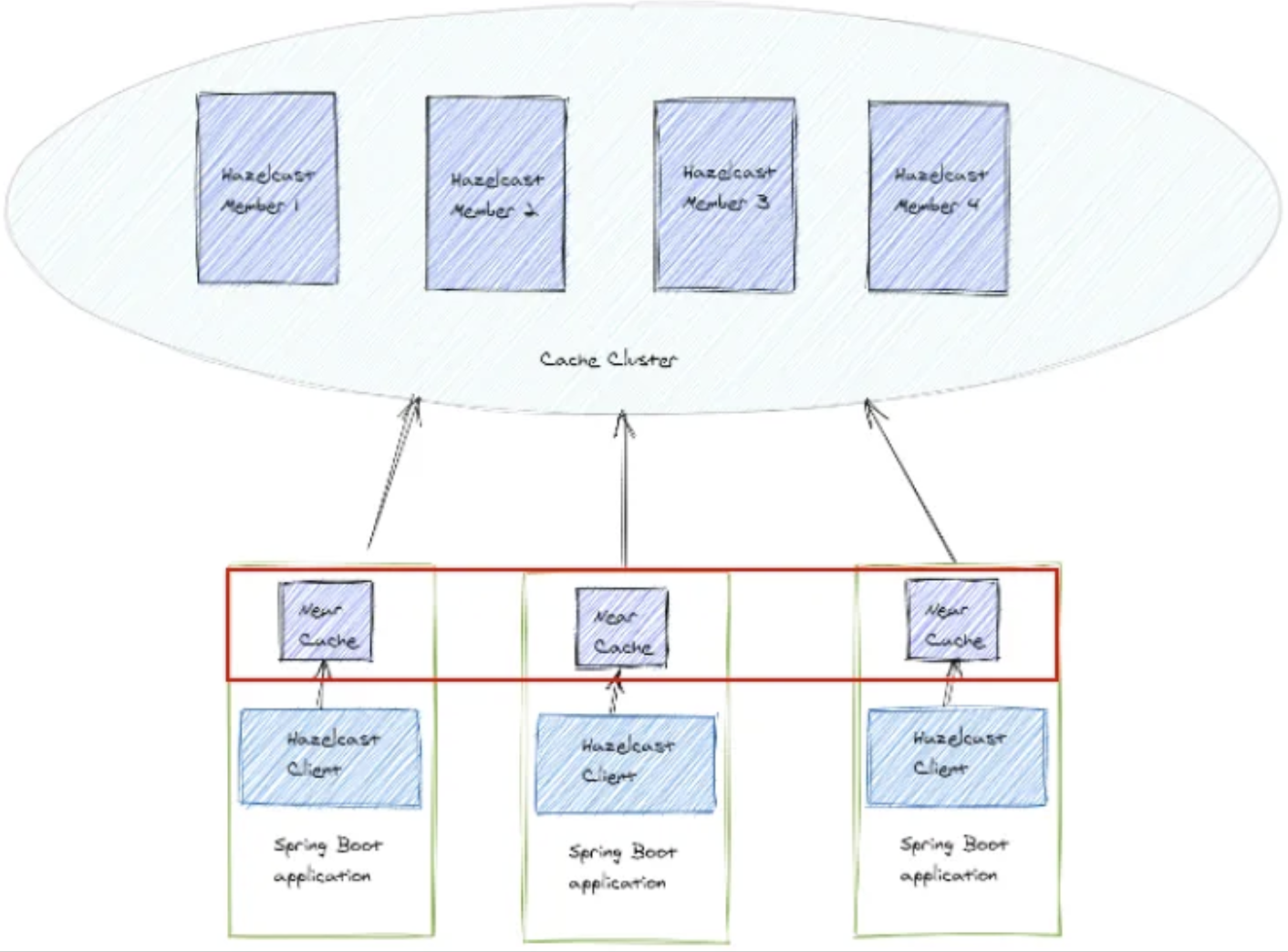
Spring Boot 연동
Spring Boot 는 Hazelcast 와의 통합을 공식적으로 지원하고 있기 때문에 CacheManager 구성이 용이하고 이를 통해 캐시 관련 어노테이션을 그대로 사용할 수 있다. 이러한 이유로 다른 팀원 입장에서 캐시로 어떤 솔루션을 쓰고 있는지에 대해 크게 신경쓸 필요가 없을 것 같아서 Hazelcast를 선택하기도 했다. (스프링이 공식적으로 지원하는 캐시라는 것만으로도 한번 사용해볼 이유가 되긴 한다)
https://docs.hazelcast.com/hazelcast/5.3/spring/overview
Integrating with Spring | Hazelcast Documentation
× Send us your feedback Thank you for helping us improve Hazelcast documentation.
docs.hazelcast.com

한편, getAsync 요청에서 Serializable 이 구현되지 않은 데이터를 저장하고 읽어올 때 timeout 이 정상적으로 동작하지 않고 client 요청이 블로킹되는 문제가 있었는데 Hazelcast 쪽에 이슈를 남긴지 반년이 지났지만 아직 답변이 오진 않았다😅 (내가 뭔가 잘못 질문했나 싶어 살펴보니 답변 기간이 그냥 느린 것 같다...)
https://github.com/hazelcast/hazelcast/issues/26454
HazelcastCache.getAsync() timeout issue in Hazelcast Client · Issue #26454 · hazelcast/hazelcast
Describe the bug We are using Hazelcast 5.3.6 and Hazelcast Client 5.3.6. When I attempt to retrieve cached data asynchronously using HazelcastCache.getAsync() (where the data has a read timeout of...
github.com
모니터링 연동
Hazelcast 는 다양한 모니터링 도구를 손쉽게 연동할 수 있도록 설정을 제공하고 이를 통해 매트릭을 추적할 수 있다.
나 역시 Management Center, prometheus -> grafana 연동으로 모니터링을 구성해 운영 간 사용하고 있다. Management Center 는 무료로 제공하는 모니터링 도구치고 UI 도 깔끔하고 제공하는 기능(Heap 사용량, CPU 사용량, read/write 부하 모니터링 등등) 도 좋은 것 같다.
다만, Management Center 는 라이센스가 없으면 클러스터 멤버를 최대 3개 밖에 모니터링 할 수 없다는 단점이 있긴 하다.

이 외 멤버의 세부 설정은 권장 옵션에 따라 세팅을 했다.
파티션 설정
각각의 파티션은 50~100MB 수준의 데이터를 저장하는 것을 권장한다. (default partition 271 기준 25~30 GB 데이터를 저장할 때 좋은 효율을 보임)
이미지, GC 설정
hazelcast 는 최선 버전의 JDK 를 사용하는 것을 권장하고 있고(v5.3 기준 jdk17 까지 지원), JVM heap 16GB 이하, G1GC 환경에서 좋은 퍼포먼스를 보이고 G1GC 의 GCPause 로 인한 지연 시간은 옵션으로 최대 5ms 까지 낮추길 권장한다.
Gracefulshutdown 설정
또한, member 가 다운되었을 때 데이터 손실 없이 다른 노드로 데이터로 마이그레이션 될 수 있도록 gacefulshutdown 옵션을 활성화 했다.
Failover, Fail-Fast 구성
Hazelcast 운영에 앞서 발생할 수 있는 장애 시나리오를 찾고 Failover, Fail-Fast 구성도 추가했다.
Hazelcast Client 는 기본적으로 아래와 같은 순서로 Member 와 Connection 을 유지하는데
- 주기적으로 heartbeat 를 보낸다
- heartbeat-timeout 이 되면 member 와의 connection 을 끊고 (일정 시간 뒤) 재연결 요청을 한다
- 재연결이 실패하면(= 연결할 수 있는 member 가 존재하지 않으면), retry(reconnect) 단계로 들어간다
- cluster-connect-timeout 이 되면 더 이상 connect 요청을 하지 않는다
여기서 아래와 같은 Client의 기본 옵션으로 인해 장애가 발생할 수 있다.
- Hazelcast Client 의 default 옵션으로 retry 는 SYNC 로 동작
- HazelcastCache 의 read timeout 이 설정되어 있지 않다
문제1.
Member 가 다운되었을 때 Retry 가 SYNC 모드이기 때문에 연결이 재수립될 때까지 캐시를 사용하는 요청이 블로킹된다
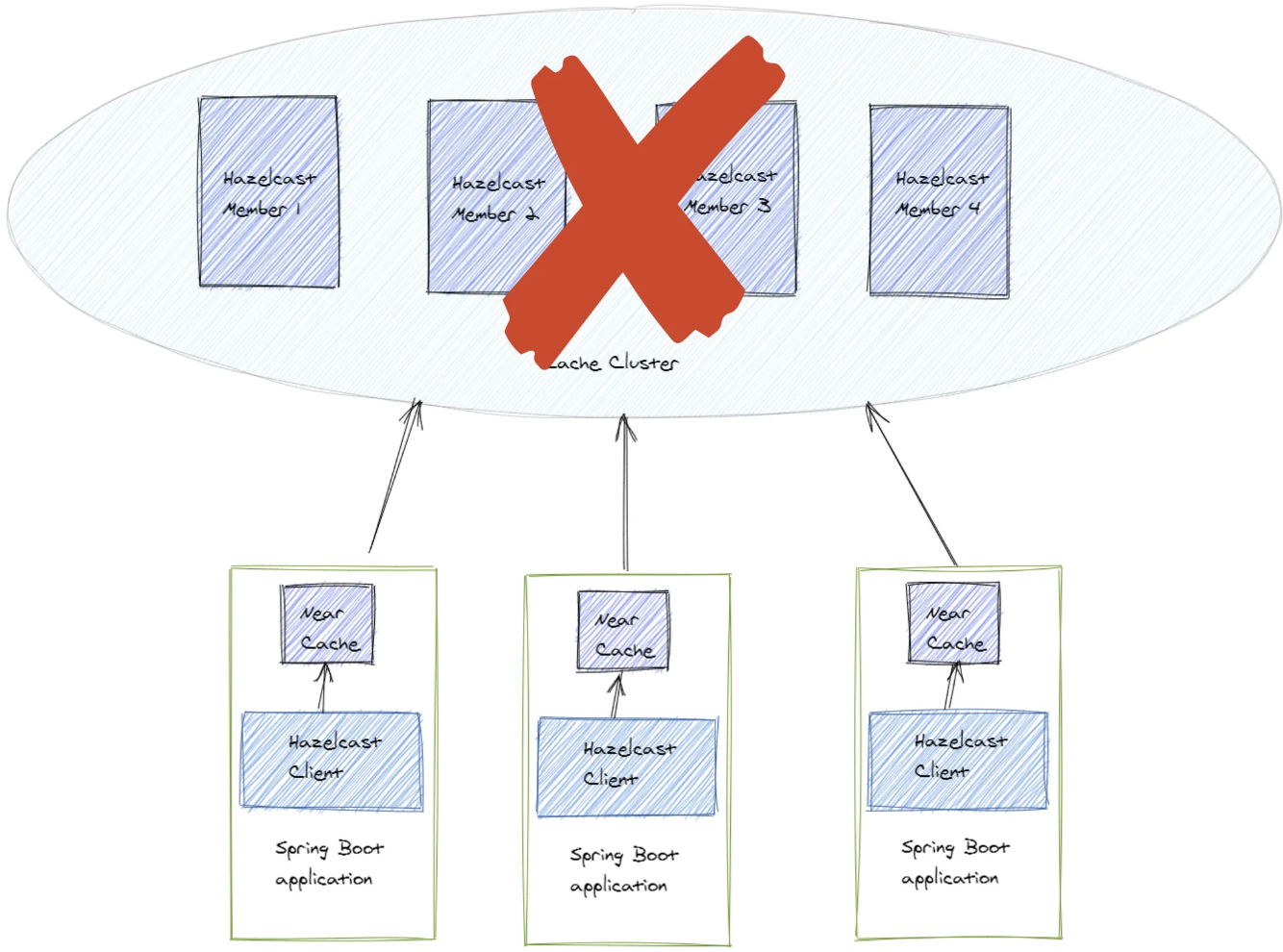
문제2.
네트워크 지연이 발생하거나 클러스터 부하가 심해져 데이터를 가져오는 속도가 느릴 때 클라이언트의 응답 시간에 영향(latency) 을 미칠 수 있다

위와 같은 문제를 해결하기 위해
- heartbeat interval 및 timeout을 설정하고 총 i번의 응답 확인을 거쳐 connection 유지 여부 판단을 하도록 설정했다.
- retry 단계로 돌입하기 전 연결 요청에 대한 timeout 은 j초로 설정했다. (= j초간 연결 요청에 대한 응답이 없을 시 retry 단계로 돌입)
- reconnect-mode(retry) 의 경우 ASYNC 로 설정, 연결이 끊어진 상태에서 즉시 예외를 돌려주도록 해 이에 대한 즉각적인 핸들링이 가능하도록 했다.
- retry 요청의 경우 timeout 을 infinite 로 설정해 클러스터가 다시 회복될 때까지 재연결 요청이 가능하도록 했고 클라이언트가 많을 경우 요청이 몰리는 경우가 있기 때문에 exponential backoff + jitter 로 재연결 시도하도록 구성했다.
실제로 운영 간에 팀 내 배포가 한번 잘못되어 클러스터 연결이 아예 끊어졌을 때가 있었는데 ASYNC 및 read timeout 구성으로 클러스터 장애를 감지하고 DB 에서 데이터가 서빙되도록 하여 네트워크가 복구되기까지 조금의 latency 상승 외에는 큰 영향 없이 서비스가 지속되었다.
마무리
블로그에 Hazelcast 관련 포스팅만 늘어나는 것 같은데 Hazelcast 사용자로써 아직 사용해보지 않은 기능들이 더 많기도 하고 많은 시나리오를 겪어보진 않은 것 같아서 앞으로도 천천히 운영 노하우를 길러보려고 한다
1년 정도 Hazelcast 를 사용해본 입장에서는 컨테이너 오케이스트레이션 환경이 디폴트가 된 요즘의 개발 환경에 적합한 솔루션을 찾고 운영해보면서 '아 이거 정말 못 써먹겠네' 하는 생각 없이 사용했다는 것만으로도 다른 사람들에게 추천할 수 있는 기술이라고 생각한다.
특히, 팀 내에서 k8s 환경에 캐시 클러스터를 구성할 일이 있다면 Hazelcast 를 고려해보는 것을 추천한다
이 외에도 포스팅 하고 싶은 다른 주제도 많은데 꼭 시간 내서 하나씩 써봐야겠다
잘못되거나 궁금한 내용 알려 주시면 감사하겠습니다!
'infra' 카테고리의 다른 글
| Github Actions 괜찮네 (7) | 2024.02.11 |
|---|---|
| [Hazelcast] Distributed Computing (Predicate) (2) | 2023.09.28 |
| [Kafka] 메세지큐 서버 도입과 역할의 분리 (2) | 2023.01.10 |
| [CI/CD] 프로젝트 무중단 배포 도입기 (2) | 2023.01.04 |
| [CI/CD] Docker 에서 SpringBoot 구동하기 (2) | 2022.07.24 |



